What is Parsefy?
Parsefy is a universal document extraction engine that transforms unstructured documents into structured JSON data using AI-powered precision. Simply define what data you need using a schema, upload your document, and get perfectly structured data back.Schema-Driven
Define exactly what you need with JSON Schema or Pydantic models
Multi-Format Support
Process PDFs with native multimodal AI and DOCX files
High Accuracy
Intelligent fallback architecture ensures reliable extractions
Accurate Extraction
Strict extraction rules minimize errors and false data
Key Features
| Feature | Description |
|---|---|
| Schema Adherence | 100% compliance with your JSON Schema definition |
| PDF Processing | Native multimodal AI processing for PDFs |
| DOCX Support | Automatic Markdown conversion for Word documents |
| Smart Fallback | Automatic escalation to more capable models when needed |
| Confidence Metrics | Built-in quality scoring (0.0 - 1.0) with issue tracking |
| Rate Limiting | Built-in protection with credits-based and request-rate limits |
| Playground Mode | Test without an API key (10 credits/day) |
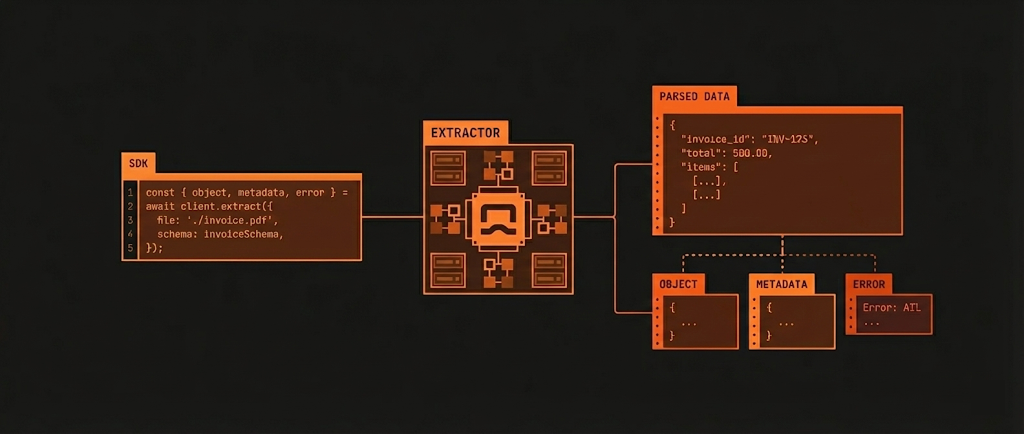
How It Works
1
Define Your Schema
Create a JSON Schema or use Pydantic/Zod models to define the data structure you want to extract.
2
Upload Your Document
Send your PDF or DOCX file to the API along with your schema.
3
Get Structured Data
Receive perfectly structured JSON data matching your schema, complete with confidence scores.